We study the attention sink phenomenon — where a few tokens monopolize attention regardless of content — in Diffusion Transformers (DiTs). This has been widely studied in large language models but remains underexplored in DiTs, whose architectural differences prevent existing explanations from directly transferring.
Six DiT architectures spanning three PE types and two attention designs.
| Model | PE Type | Sink Region | Peak Ratio | Unique Sinks |
|---|---|---|---|---|
| PixArt-α | AbsPE |
Spatial corners | 85× | 20 |
| FLUX.1 | 2D RoPE |
Text <PAD> |
214× | 7 |
| Qwen-Image | 2D RoPE |
Text tokens | 240× | 7 |
| Z-Image | 3D RoPE |
Text <PAD> |
212× | 5 |
| Wan2.1 | 3D RoPE |
1st-frame patches | 477× | 48 |
| LTX Video | 3D RoPE |
1st-frame patches | 65× | 91 |
Peak = max sink-to-random μk ratio across all layers. Unique = number of distinct top-1 sink tokens across ≥100 prompts (low = deterministic, high = stochastic).
Sink-to-random μk ratio across network depth for representative DiTs.
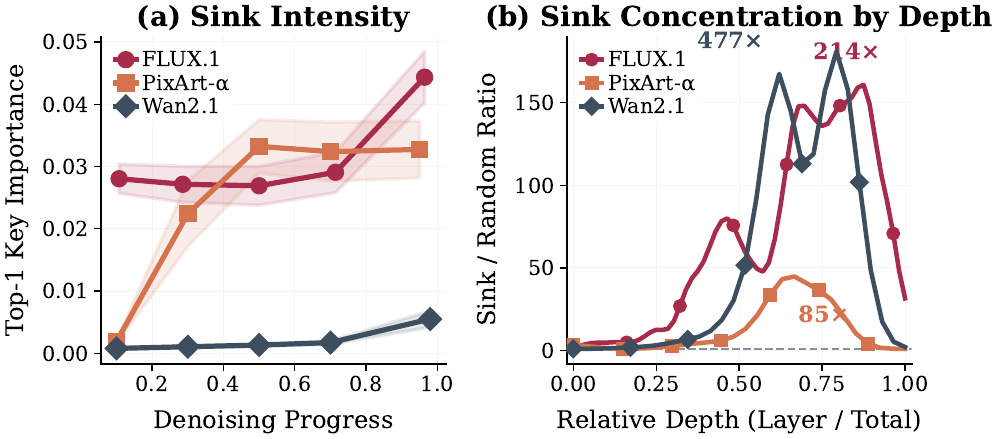
We track sink strength along two axes: denoising progress and network depth. All three representative models develop sinks within the first few steps. FLUX.1 shows high Key Importance from step 1; PixArt locks onto a fixed sink around step 6; Wan grows exponentially over the first 20 steps.
Across layers, a sharp transition occurs in the second half of the network: attention concentrates onto a few tokens, reaching 85× (PixArt), 214× (FLUX.1), and 477× (Wan) at peak. Shallow layers show uniform attention.
The sink identity is determined by the positional encoding type. In AbsPE models (PixArt-α), sinks are corner tokens whose learned embedding has extreme coordinate values. In 2D RoPE models (FLUX.1, Qwen-Image), sinks land on text tokens. Z-Image uses 3-axis RoPE and also selects text <PAD> tokens, while 3D RoPE video models (Wan2.1, LTX Video) cluster sinks on first-frame patches.
Across all PE types, sink tokens share two properties: they occupy stable positions (present in every forward pass) and carry minimal content (not directly supervised by the training loss).

In LLMs, attention sinks co-occur with massive activations — outlier hidden-state dimensions that appear in the same tokens. We observe the same co-occurrence in DiTs: sink tokens exhibit activation spikes ~50× above average.
However, DiTs typically apply QK-Normalization, which projects all Key vectors to the same ℓ2-norm. After normalization, sink and non-sink tokens have identical Key magnitudes. The cause must lie in the direction of the Key vectors rather than their magnitude.
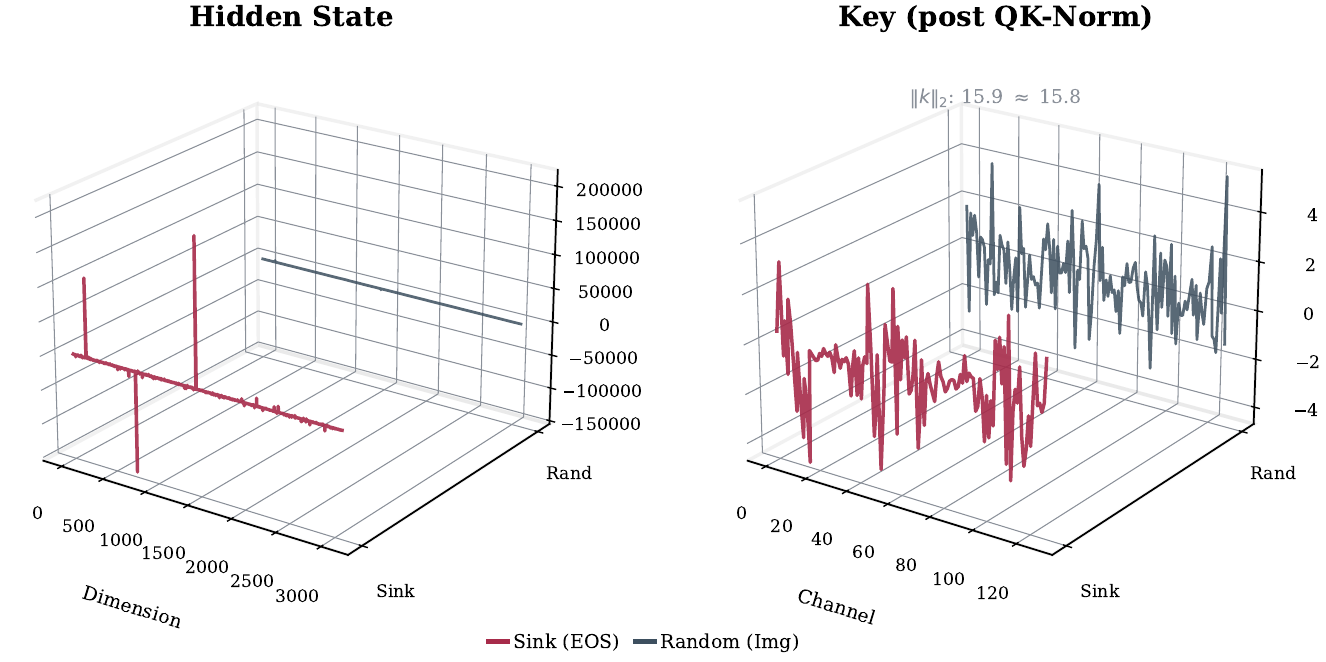
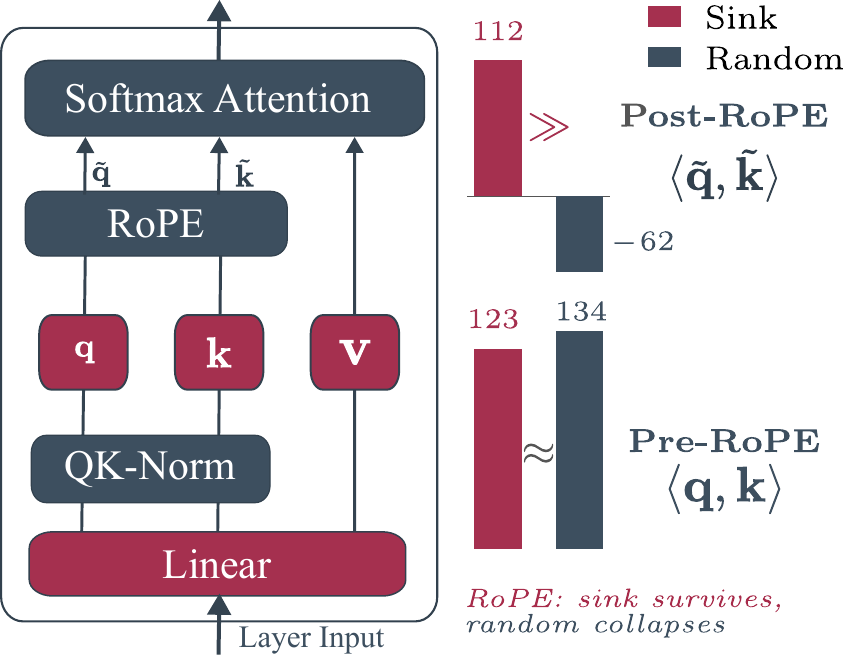
RoPE is the only operation between QK-Normalization and the dot product. We compute the mean ⟨q, k⟩ for a sink key versus a random image key, before and after RoPE:
Pre-RoPE: both keys score similarly (123 vs 134) — no sink would form. Post-RoPE: the sink key retains its score (112) while the random key drops to −62. RoPE does not boost the sink; it suppresses non-sink keys by rotating their channels in ways that reduce dot products with distant queries.
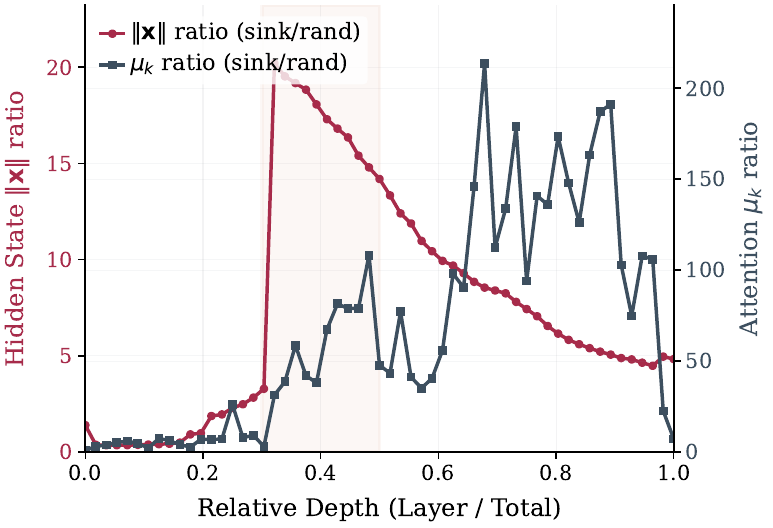
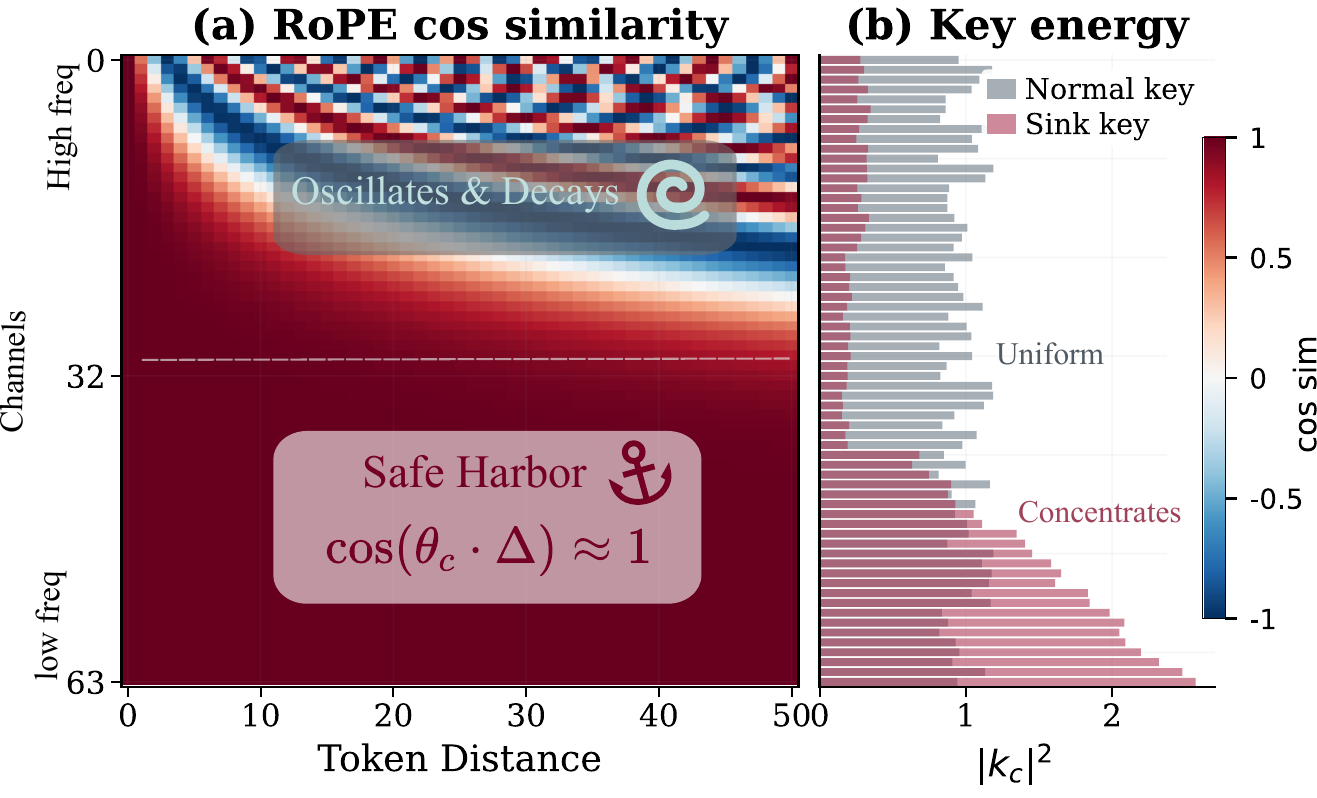
RoPE assigns each channel pair a rotation frequency θc. High-frequency channels rotate rapidly and their contributions cancel out for distant tokens. Low-frequency channels barely rotate: cos(Δθc) ≈ 1 regardless of distance — a "Safe Harbor".
Sink keys concentrate the majority of their energy into these low-frequency channels, while normal keys spread energy uniformly and lose it to high-frequency cancellation. We call this Frequency-Aware Concentration (FAC). It deepens with layer depth, reaching >200× attention gap in the deepest layers. On the Value side, sink tokens carry near-zero magnitudes — they absorb attention without adding signal.
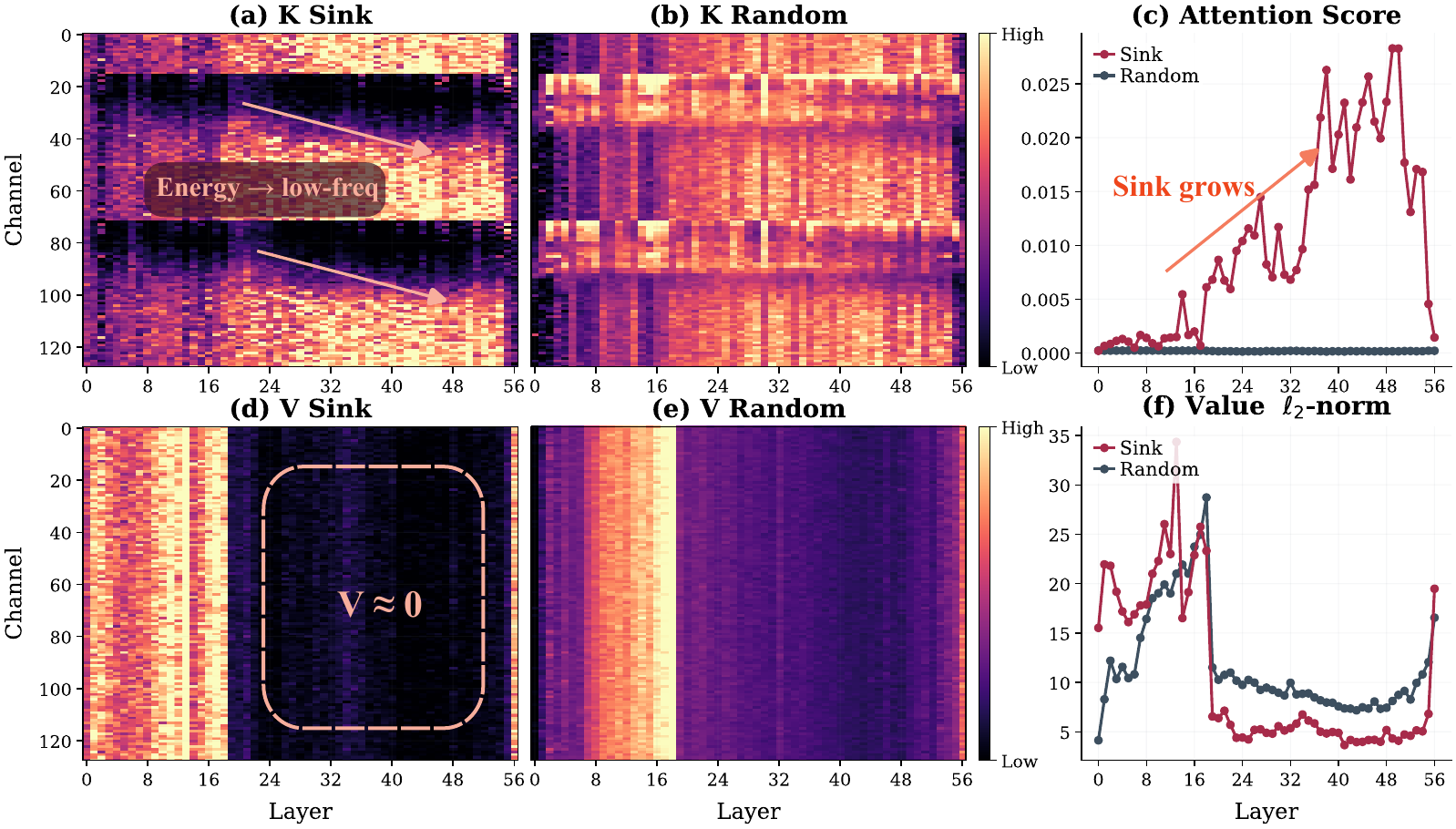
FAC explains how a token wins attention, but which tokens acquire this advantage depends on the PE type:
RoPE models: semantically empty tokens (<PAD>, <EOS>) that carry no content become sinks. In FLUX.1, <EOS> receives 1165× uniform attention, <PAD> 117×, commas only 29×.
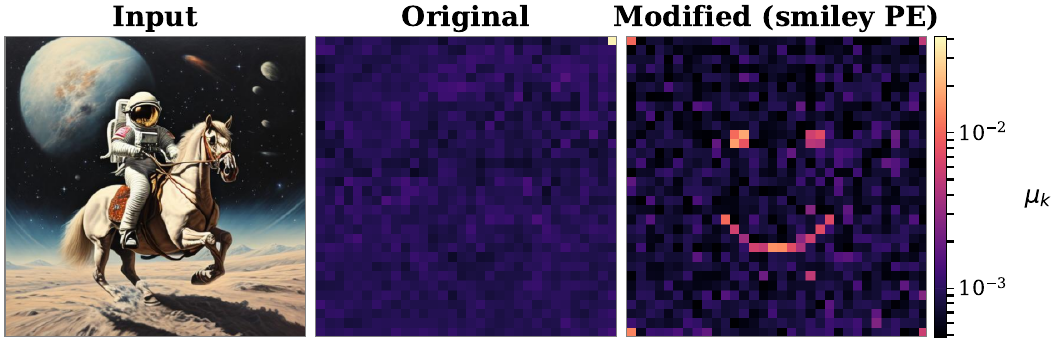
AbsPE models: the learned positional embedding itself controls sink identity. We verify this causally: zeroing the corner PE and copying it to 20 positions arranged in a smiley-face pattern redirects attention to those positions (8.6× higher μk).
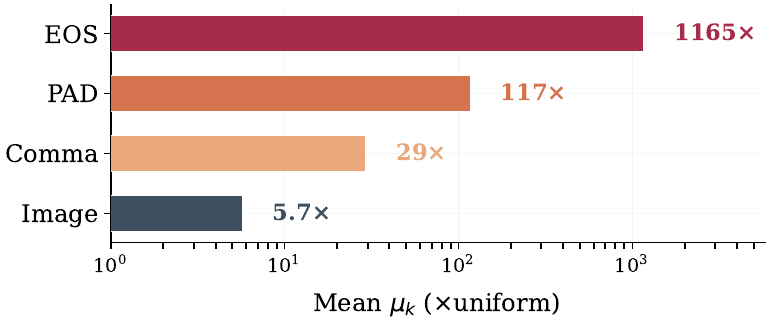
FLUX.1 uses a T5 encoder that packs every prompt into a fixed 512-token sequence. A typical short prompt fills ~17 slots; the remaining ~494 are <PAD> tokens. These empty tokens satisfy the FAC condition and become strong sinks: <PAD> tokens collectively absorb 55% of the total attention budget, while the 4,096 image tokens (89% of the sequence) receive only 22%.
Since comma tokens attract only 29× uniform attention versus 117× for <PAD>, simply appending 200 commas to the prompt displaces most padding tokens and redistributes attention toward image tokens. No retraining or architectural change is needed.
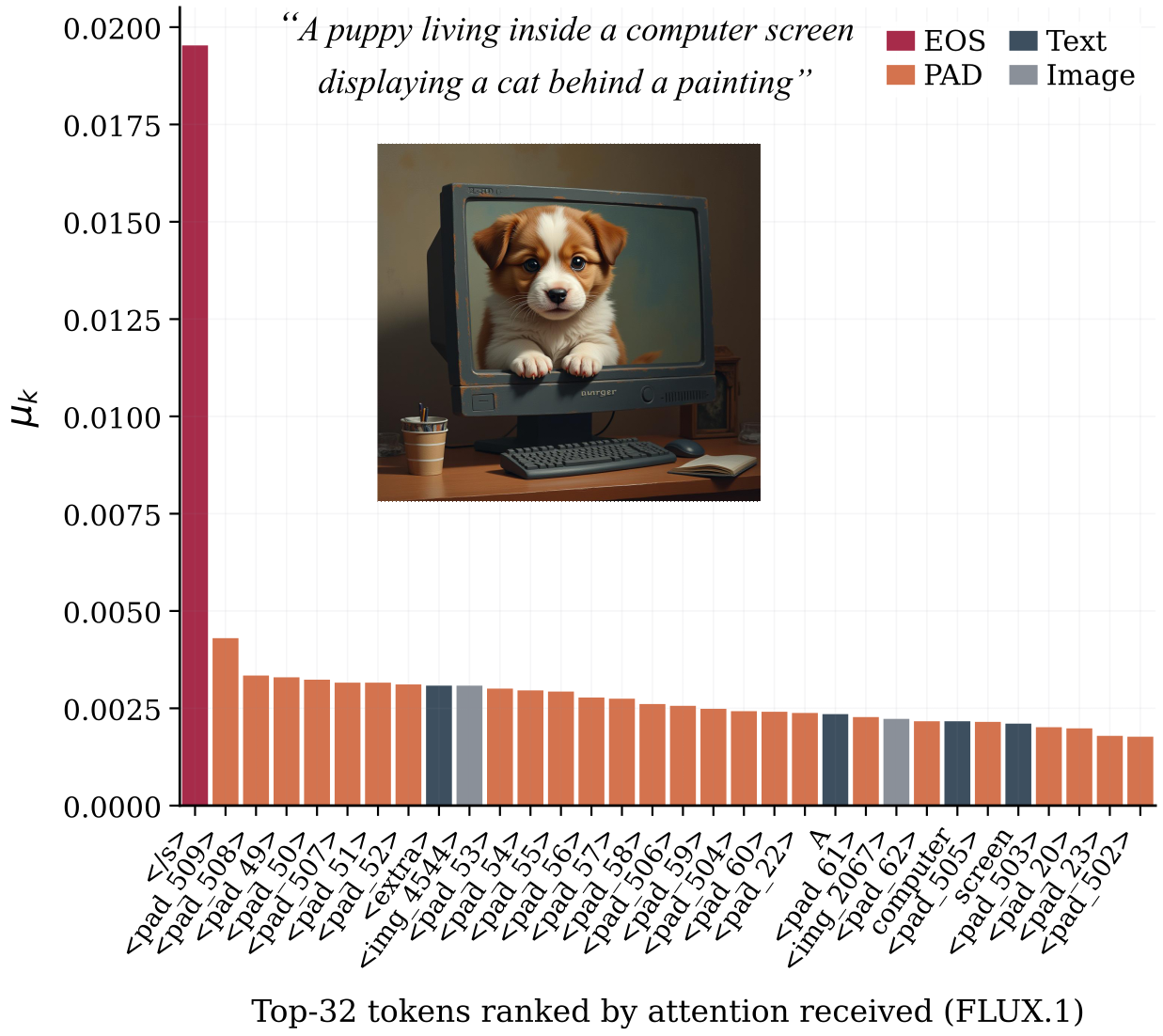
Evaluated on FLUX.1-dev (12 steps, 1024², guidance 3.5). Comma padding improves compositional categories while maintaining general quality (TIIF overall: 66.8% → 67.7%).
| Benchmark | Category | Baseline | +Comma | Diff |
|---|---|---|---|---|
| Concept Mixing | Conflicting concepts | 3.65 | 4.55 | +0.90 |
| Concept Mixing | Hybrid fusion | 4.37 | 5.71 | +1.34 |
| TIIF-Bench | Diff. + texture | 43.0% | 50.5% | +7.5% |
| TIIF-Bench | Comparison | 55.6% | 61.6% | +6.0% |
| TIIF-Bench | Action + 2D | 80.4% | 86.0% | +5.6% |
CM = GPT-scored alignment (0–10). TIIF = VQA accuracy. Trade-off: aesthetic scores decrease ~19% on Concept Mixing (comma padding shifts the alignment–aesthetics frontier).
Hover, focus, or tap to compare the +Comma result. Same model weights, same seeds — only the prompt suffix differs.












@misc{yang2026spiral2sink,
title = {From a Spiral to a Sink: How Positional Encoding
Shapes Attention Sinks in Diffusion Transformers},
author = {Yang, Yuanbo and Shao, Jiahao and Gao, Jun and Liao, Yiyi},
note = {Manuscript under review},
year = {2026}
}